Medical IT
An introduction to SELENA+Overview
-
Components of SELENA+
-
• SELENA+ DLS: Deep Learning System
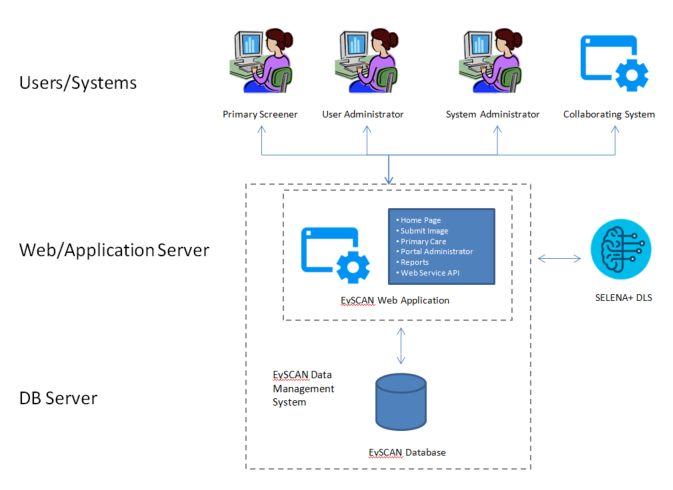
• EySCAN: Data Management SystemSELENA+ consists of EySCAN Data Management System (EySCAN Web Application, EySCAN Database and EySCAN Web Service API) and SELENA+ DLS.
EySCAN Web application receive requests from user or collaborating system and get back the results to requester after invoking database or SELENA+ DLS accordingly based on the corresponding requests.
Web application invokes SELENA+ DLS to get retinal condition prediction results upon receiving submission and stores them into database together with related information of the case.
-
Automatically analyze image to detect:
-
SELENA+, an award-winning product, is an automated system that is able to detect 3 retinal diseases concurrently through analysis of colour retinal images.
• Diabetic Retinopathy
• Glaucoma Suspect
• Age-related Macular Degeneration
-
SELENA+ is jointly invented by
-
• EyRIS Pte Ltd
• Singapore Eye Research Institute
• National University of Singapore



-
Technical Articles
-
• Source: The LANCET Digital Health
Artificial intelligence using deep learning to screen for referable and vision-threatening diabetic retinopathy in Africa: a clinical validation study• Source: The JAMA (The Journal of the American Medical Association)
Development and Validation of a Deep Learning System for Diabetic Retinopathy and Related Eye Diseases Using Retinal Images From Multiethnic Populations With Diabetes
How it works
-
Diagnostic Flow
-

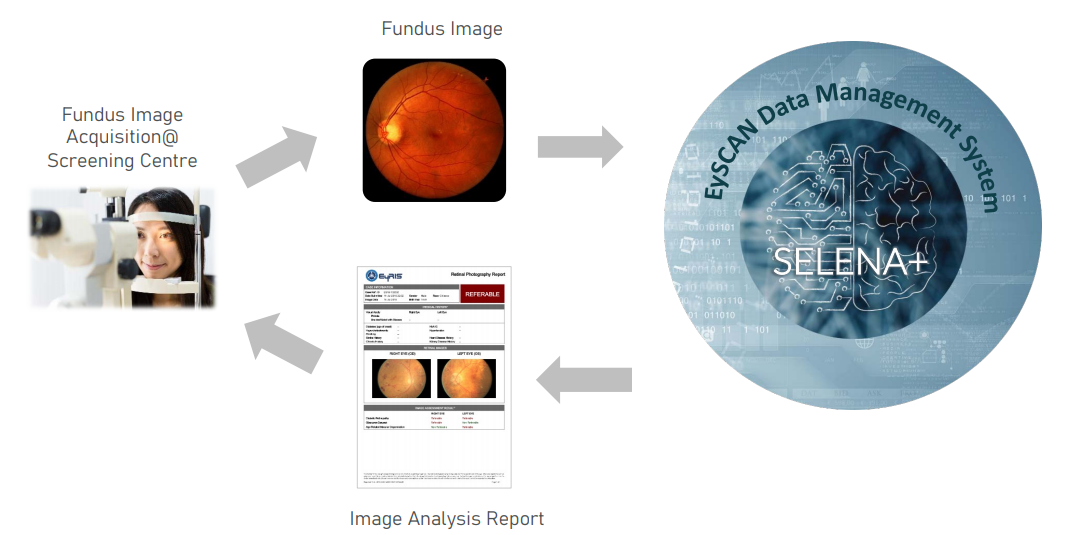
1. Image aquisition of digital Fundus photograph
2. Electronic submission of retinal image to SELENA+/EySCAN system
3. Intelligent Deep Learning Analysis of retinal image
4. Delivery of Assessment Report
AI Work Flow
SELENA+ DLS
Technical Aspects

While various network architectures such as Inception and deep residual networks have been employed, the VGGNet architecture was selected as it had been demonstrated to produce state-of-the-art performance on general image classification when our experiments were first conceptualized. Briefly speaking, the training of a deep convolutional neural network (DCNN) to classify diabetic retinopathy and other conditions is achieved by presenting the network with batches of labeled training images. The DCNN then incrementally learns the key characteristics of images belonging to each class. We trained multiple DCNNs and obtained an image score by ensembling the individual DCNN scores. The eye-level score is then obtained by averaging the image scores of available images of the eye that are of acceptable quality. A score threshold determined from the training data is then applied to the eye-level score, to obtain the eye classification for the targeted retinal condition.
As a preparatory step, each retinal fundus photograph is first automatically segmented to extract only the retina disc, since photographs from different cameras may vary slightly in capture area. This circular region of interest is then uniformly rescaled to fit a standardized square template of dimension 512x512 pixels (Figure 2a), with each pixel's color represented by its red, green and blue values in the RGB model. This template image is used with one of the DCNNs in our two-model ensemble, while a local contrast-normalized version of the original template image is used with the other DCNN (Figure 2b).
The RGB values of the template image are then input as the three channels of the first layer of the relevant DCNNs. This input layer (Figure 2c) is followed by a succession of modules. Each module begins with multiple convolutional layers (Figure 2d) that learn features at their corresponding spatial scale. Each convolutional layer contains a collection of feature maps, with the appropriate relation between them encoded by 3x3 weight kernels (Figure 2e). Thus, the value of the red pixel in Figure 2d is the weighted sum of the element-by-element convolution of the corresponding region in the previous map (red square in Figure 2c) with its weight kernel. Each module ends with a 2x2 maxpooling layer (Figure 2f) that effectively downsamples the feature dimensions by a factor of two. These maps in turn serve as the inputs to the next module, which thereby considers features at a new, reduced scale. Standard ReLU rectification and fullyconnected dropout layers are applied after the final module, before a softmax output layer that contains one output node for each class trained for (Figure 2g). Each of our DCNNs contains five such modules, and a total of 19 layers.
The training procedure for each DCNN involves repeatedly randomly sampling a batch of images from the training set, together with their ground truth classification. All the weight values of the DCNN are then adjusted by gradient descent, which incrementally improves the general association between images of a certain class, and the value of their corresponding output node. Concurrently, the DCNN automatically learns useful features at each scale represented by its models, from the smallest-possible pixel level, to scales approaching that of the original input. To expose the convolutional network to additional plausible input feature variations, we apply a limited family of transformations to the input images, involving mirroring, rotation, and scaling by a small degree. Each network was trained approximately to the convergence of its performance, on a small held-out validation set.
For the classification of DR severity, an ensemble of two convolutional networks was used. One network was provided the original images as input, while the other network was provided locally contrast-normalized images. The output nodes of each network were indexed according to increasing severity of DR class, from 0 to 4. This allows the predicted DR severity to be represented by a single scalar value, by summing the product of the value of each output node, with its index. The final DR severity score is then the mean of the outputs of the two convolutional networks. Classification of test images is then achieved by thresholding the DR severity score for desired sensitivity/specificity performance, as estimated from the validation set. For the purposes of this paper, a threshold of 0.9 was selected as being adequate for screening purposes. For the classification of AMD and glaucoma severity, a similar procedure was followed, except that each of these conditions admits only three severity classes, from 0 to 2. A threshold of 0.40 was selected for AMD, and 0.70 for glaucoma.
Additionally, convolutional networks were trained to reject images for insufficient image quality, as well as for being invalid input (i.e. not being a retinal image). For the latter model, a broad variety of natural images was used as the negative class, in training. Images rejected by either of these models are considered as being recommended for further referral, for the purposes of computing the experimental results. Once an image is analyzed, a report will be generated for the users. On average, the DLS takes approximately 5 minutes to analyze 1000 images (0.3 seconds per image), using a single graphic processing unit (GPU).
Compatible Cameras
SELENA+ DLS is compatible with at least 6 camera models from 4 camera brands:
| Brand | Model | |
| Topcon |
|
• NW8 • TRC 50DX |
| Canon |
|
• CR-DGi |
| Carl Zeiss |
|
• VISUCAM 500 • VISUCAM Pro NM |
| Crystalvue |
|
• FundusVue |
EySCAN
• EySCAN is a software solution design to automate retinal image analysis for early detection of Diabetic Retinopathy, Glaucoma and Age Related Macular Degeneration.
• EySCAN is a data management software for use only with the SELENA+. It is primarily web-based and provides the user interface for users to interact with SELENA+.
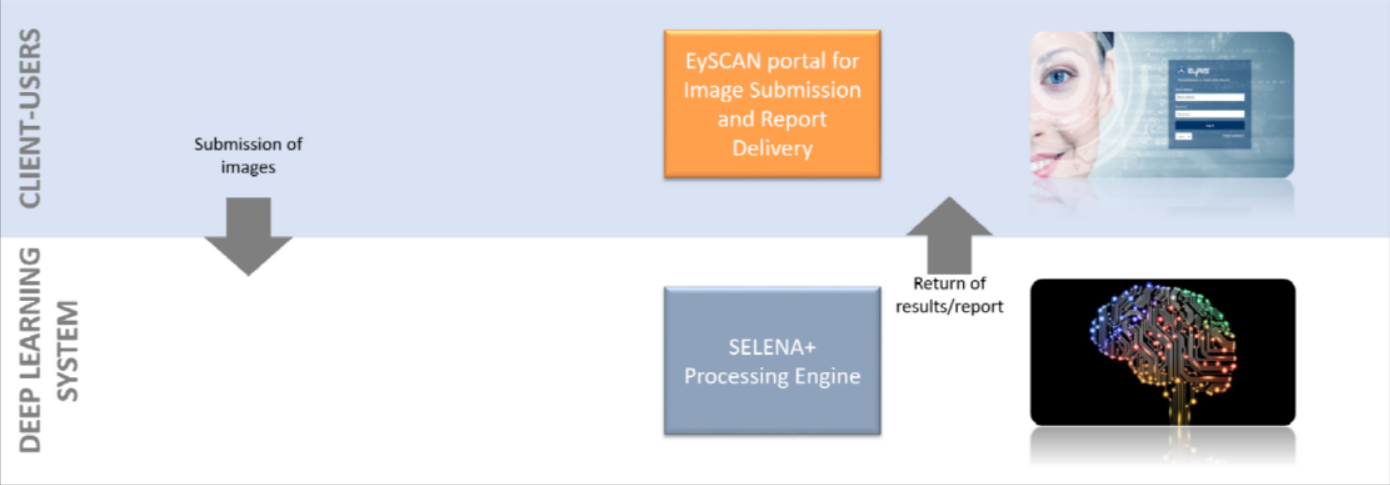
Full-Automated Retinal Analysis System
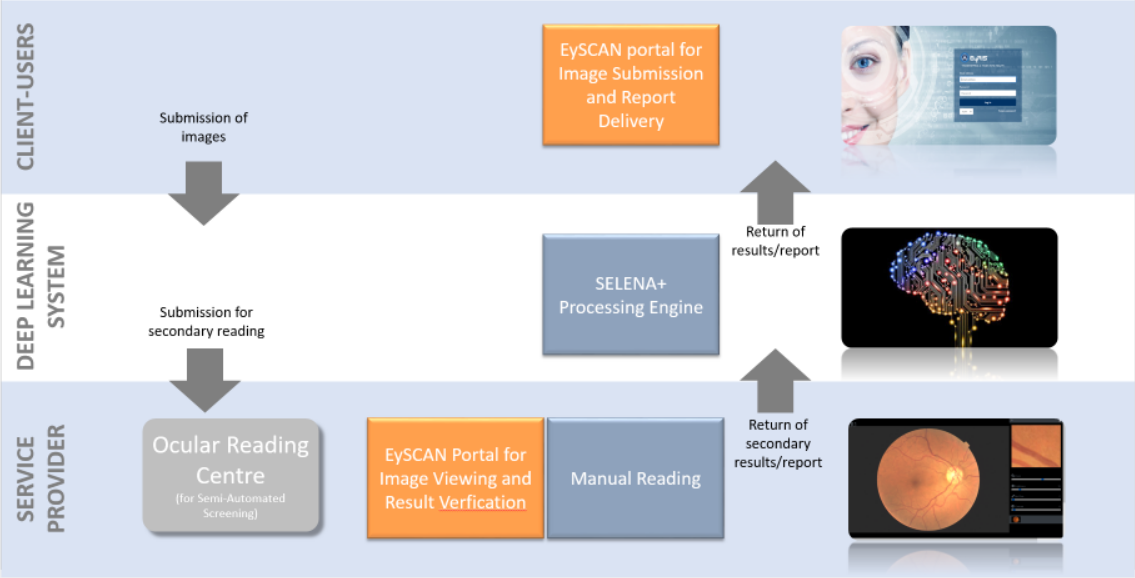
Semi-Automated Retinal Analysis System
The 3 layers of the system
1. Client-Users
Client group refers to end-users. Client-Users must have an account registered with EySCAN to make submission. Users are required to provide some details together with retinal images attached before making submissions. The images can be captured using hand-held device with fundus quality camera. Successful submissions will be routed to 2nd layer, Deep Learning System.
2. Deep Learning System
Deep Learning System (DLS) is a machine learning technology with potential for screening diabetic retinopathy and related eye diseases. It is used in SELENA+ Processing engine developed by clinicians from SERI and computer scientists from NUS to evaluate the performance of a DLS in detecting referable diabetic retinopathy, vision-threatening diabetic retinopathy, possible glaucoma, and age-related macular degeneration (AMD) in community and clinic-based multiethnic populations with diabetes. Based on the images submitted by 1st layer (Client-Users), EySCAN will transfer the submitted images over to SELENA+ Processing Engine for processing. SELENA+ will analyze submitted images and provide EySCAN with the analysis result back to Client-Users layer for users to view the result/report via EySCAN portal. At the same time, the referable cases will be assigned to Service Provider for manual grading for organizations configured with Semi-Automated (refer to Semi-Automated image). Else, the flow ends here (refer to Full-Automated image)
3. Service Provider
Service Provider refers to group of users of Ocular Reading Centre. For images that are found to be referable, system will route the case to secondary grader. Users with secondary grader access rights will need to take the cases for further manual reading and checking (refer to Semi-Automated image). If results are found to be different from the generated result, users should be able to amend the results. Based on the final verification by them, the final result/report will be returned back to EySCAN portal in Client-Users layer to release the final result to patient.Comparison
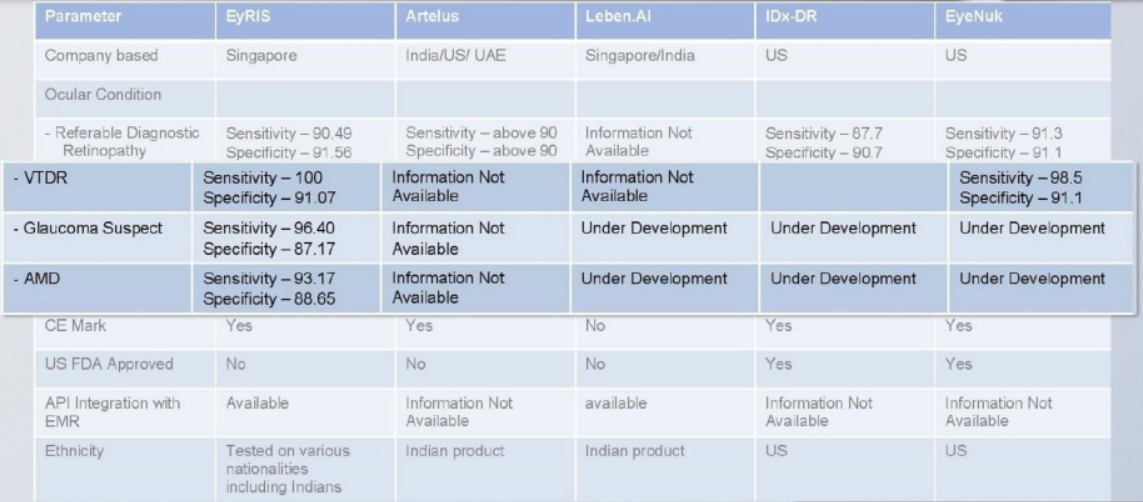
Ourstanding performance
Test measurements as published in
The Journal of the American Medical Association (12 Dec 2017)
shows very promising and consistent results at over 90% sensitivity and specicity in detecting
referable DR and over 95% for vision-threatening DR.
The repeatability (same image tested twice) and negative predictive value were 100%
and more than 99%, respectively.
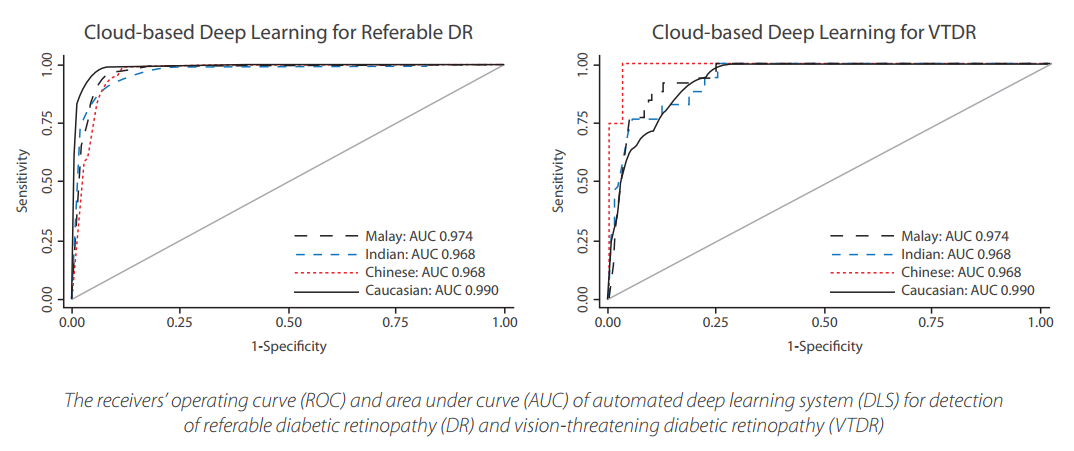
This has proven that SELENA+ with its DLS is a reliable and accurate tool that can consistently provide a timely and cost eective strategy to assess retina images for DR screening programs.
-
According to partners, SELENA+ has
-
• Shortened diagnosis procedure from 30 min to 8.5 min
• Accelerated diagonosis by 3.5x
• 74.7% improvement in efficiency
• Caused greater patients satisfaction
Next Steps
Extending features
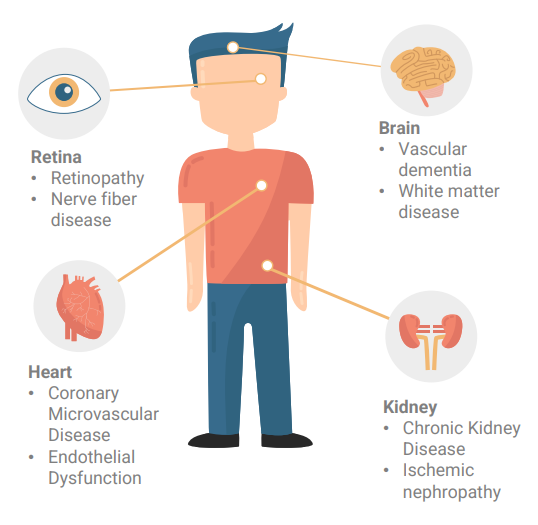
• Embryonic vessels found in the retina are formed while still an embryo.
• Retina, Brain, Kidney and Heart share same physiological and anatomical changes.
• Using big data to detect Cardiovascular Disorders (CVD) e.g., CKD(Chronic Kidney Disease), CVA(CerebroVascular Accident), Hypertension and possibly dementia.
Clinical Trial
Do you want to try this solution?
Please wait a moment.
Procedures are underway to obtain permission from the Ministry of Food and Drug Safety of Korea.
We'll contact you as soon as possible, if you leave a message.